
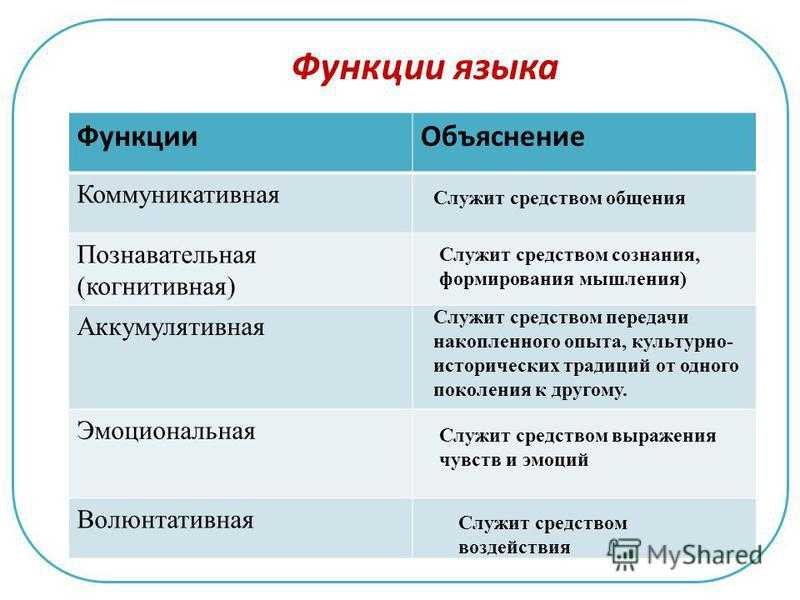
Многомерный случай
Определение двух случайных величин
При одновременной работе с более чем одной случайной величиной совместная кумулятивная функция распределения также можно определить. Например, для пары случайных величин Икс,Y{ displaystyle X, Y}, совместный CDF FИксY{ displaystyle F_ {XY}} дан кем-то:п. 89
| FИкс,Y(Икс,у)=п(Икс≤Икс,Y≤у){ displaystyle F_ {X, Y} (x, y) = operatorname {P} (X leq x, Y leq y)} |
|
(Уравнение 3) |
где правая часть представляет собой вероятность что случайная величина Икс{ displaystyle X} принимает значение меньше или равно Икс{ displaystyle x}и который Y{ displaystyle Y} принимает значение меньше или равно у{ displaystyle y}.
Пример совместной кумулятивной функции распределения:
Для двух непрерывных переменных Икс и Y: Pr(а<Икс<б иc<Y<d)=∫аб∫cdж(Икс,у)dуdИкс{ Displaystyle Pr (a ;
Для двух дискретных случайных величин полезно создать таблицу вероятностей и определить кумулятивную вероятность для каждого потенциального диапазона Икс и Y, а вот пример:
учитывая совместную функцию плотности вероятности в табличной форме, определите совместную кумулятивную функцию распределения.
| Y = 2 | Y = 4 | Y = 6 | Y = 8 | |
| Икс = 1 | 0.1 | 0.1 | ||
| Икс = 3 | 0.2 | |||
| Икс = 5 | 0.3 | 0.15 | ||
| Икс = 7 | 0.15 |
Решение: используя данную таблицу вероятностей для каждого потенциального диапазона Икс и Y, совместная кумулятивная функция распределения может быть построена в табличной форме:
| Y < 2 | 2 ≤ Y < 4 | 4 ≤ Y < 6 | 6 ≤ Y < 8 | Y ≤ 8 | |
| Икс < 1 | |||||
| 1 ≤ Икс < 3 | 0.1 | 0.1 | 0.2 | ||
| 3 ≤ Икс < 5 | 0.1 | 0.3 | 0.4 | ||
| 5 ≤ Икс < 7 | 0.3 | 0.4 | 0.6 | 0.85 | |
| Икс ≤ 7 | 0.3 | 0.4 | 0.75 | 1 |
Определение более двух случайных величин
За N{ displaystyle N} случайные переменные Икс1,…,ИксN{ Displaystyle X_ {1}, ldots, X_ {N}}, совместный CDF FИкс1,…,ИксN{ Displaystyle F_ {X_ {1}, ldots, X_ {N}}} дан кем-то
| FИкс1,…,ИксN(Икс1,…,ИксN)=п(Икс1≤Икс1,…,ИксN≤Иксп){ Displaystyle F_ {X_ {1}, ldots, X_ {N}} (x_ {1}, ldots, x_ {N}) = operatorname {P} (X_ {1} leq x_ {1}, ldots, X_ {N} leq x_ {n})} |
|
(Уравнение 4) |
Толкование N{ displaystyle N} случайные величины как случайный вектор Икс=(Икс1,…,ИксN)Т{ Displaystyle mathbf {X} = (X_ {1}, ldots, X_ {N}) ^ {T}} дает более короткое обозначение:
- FИкс(Икс)=п(Икс1≤Икс1,…,ИксN≤Иксп){ displaystyle F _ { mathbf {X}} ( mathbf {x}) = operatorname {P} (X_ {1} leq x_ {1}, ldots, X_ {N} leq x_ {n}) }
Характеристики
Каждый многомерный CDF:
- Монотонно неубывающая по каждой из своих переменных,
- Непрерывна справа по каждой из своих переменных,
- ≤FИкс1…Иксп(Икс1,…,Иксп)≤1,{ displaystyle 0 leq F_ {X_ {1} ldots X_ {n}} (x_ {1}, ldots, x_ {n}) leq 1,}
- LimИкс1,…,Иксп→+∞FИкс1…Иксп(Икс1,…,Иксп)=1 иLimИкся→−∞FИкс1…Иксп(Икс1,…,Иксп)=,для всехя.{ displaystyle lim _ {x_ {1}, ldots, x_ {n} rightarrow + infty} F_ {X_ {1} ldots X_ {n}} (x_ {1}, ldots, x_ {n }) = 1 { text {и}} lim _ {x_ {i} rightarrow — infty} F_ {X_ {1} ldots X_ {n}} (x_ {1}, ldots, x_ {n }) = 0, { text {для всех}} i.}
Вероятность того, что точка принадлежит гипер прямоугольник аналогичен одномерному случаю:
- FИкс1,Икс2(а,c)+FИкс1,Икс2(б,d)−FИкс1,Икс2(а,d)−FИкс1,Икс2(б,c)=п(а<Икс1≤б,c<Икс2≤d)=∫…{ displaystyle F_ {X_ {1}, X_ {2}} (a, c) + F_ {X_ {1}, X_ {2}} (b, d) -F_ {X_ {1}, X_ {2} } (a, d) -F_ {X_ {1}, X_ {2}} (b, c) = operatorname {P} (a
Недостатки кумулятивной функции
Несмотря на то, что кумулятивные функции широко используются для анализа данных и моделирования статистических процессов, они также имеют свои недостатки:
Величина выборки может оказывать существенное влияние на результаты кумулятивной функции. Небольшие выборки могут привести к искаженным данным и неверным выводам.
Кумулятивная функция не учитывает временные изменения в данных
Она просто накапливает значения, не принимая во внимание динамику процесса или различные факторы, влияющие на данные.
Кумулятивная функция может быть чувствительна к выбросам или аномальным значениям в данных. Одно отклонение может существенно изменить форму кумулятивной функции и привести к неправильным выводам.
Интерпретация результатов кумулятивной функции может быть сложной
Различные формы кумулятивной функции могут иметь разные смысловые интерпретации, и это может усложнить анализ данных.
Кумулятивная функция не предоставляет информации о причинно-следственных связях между переменными. Она позволяет только наблюдать накопленные значения, но не объясняет, почему эти значения изменяются.
В целом, несмотря на некоторые недостатки, кумулятивная функция остается полезным инструментом для анализа данных, но ее результаты следует интерпретировать с осторожностью и учитывать контекст и ограничения метода
Функциональное программирование
Функциональное программирование является одним из парадигм языка программирования. Оно базируется на идее, что программа представляет собой набор функций, которые манипулируют данными. В функциональном программировании основной акцент делается на использовании функций и избегании изменяемого состояния. Центральным понятием в функциональном программировании является аккумулятивная функция.
Аккумулятивная функция в функциональном программировании является основной строительной единицей программы. Она представляет собой функцию, которая принимает на вход некоторое состояние, а также некоторые входные данные, и возвращает новое состояние. Таким образом, аккумулятивная функция накапливает результаты применения функций к данным и обновляет состояние с каждой итерацией.
В функциональном программировании аккумулятивная функция используется для работы с коллекциями данных. Она может служить для суммирования значений, фильтрации, трансформации и т.д. Аккумулятивная функция позволяет обрабатывать данные последовательно и накапливать результаты применения функций к ним. Это позволяет сделать программу более модульной и гибкой, так как функции могут быть легко комбинированы и переиспользованы.
Одним из преимуществ функционального программирования является возможность обрабатывать большие объемы данных параллельно. Такие операции, как суммирование, фильтрация и многие другие, могут быть распараллелены, что позволяет эффективно использовать многоядерные процессоры. Аккумулятивная функция способствует созданию параллельных алгоритмов, которые могут быть применены для обработки данных одновременно.
Обобщение состояния
Аккумулятивная функция языка – одна из основных характеристик языка программирования. Она заключается в способности языка накапливать и сохранять информацию или результаты выполнения операций для дальнейшего использования.
Аккумулятивная функция языка позволяет производить преобразования и манипуляции с данными, сохраняя промежуточные результаты. Это позволяет повысить эффективность работы программы и удобство ее использования.
Функции аккумуляции могут использоваться для обобщения состояния объектов или данных. Например, можно использовать аккумулятивные функции для подсчета суммы чисел в списке, сбора информации по условию или выполнения других операций, необходимых для обработки данных.
Чем более гибким и мощным является язык программирования в плане аккумулятивной функции, тем больше возможностей он предоставляет разработчикам для создания сложных и эффективных программных решений.
Постепенное изменение
Язык в своей сути является аккумулятивным. Это значит, что в процессе своего развития, он постепенно изменяется, накапливая новые слова, значения и правила. Функция аккумулятивная позволяет языку адаптироваться к меняющимся потребностям общества и приспосабливаться к новым реалиям.
Аккумулятивность языка проявляется в различных его аспектах. Во-первых, новые слова и выражения постепенно добавляются в лексикон языка, что позволяет обогатить его словарный запас и точнее передавать новые понятия и идеи. Во-вторых, значения существующих слов могут изменяться или приобретать новые оттенки, под влиянием культурных, социальных и технологических изменений.
Функция аккумулятивная языка важна для его развития и сохранения актуальности. Благодаря постепенному изменению, язык способен адаптироваться к новым ситуациям и задачам, оставаясь эффективным средством общения и передачи знаний. Однако аккумулятивность может приводить и к некоторым сложностям, связанным с семантикой и многозначностью слов
Поэтому важно активно изучать и развивать языковую компетенцию, чтобы эффективно использовать аккумулятивные возможности языка
Гауссово Распределение
Гауссовское распределение, названное в честь Карла Фридриха Гаусса, находится в центре внимания многих областей статистики.
Данные из многих областей исследования неожиданно могут быть описаны с использованием распределения Гаусса, настолько, что распределение часто называют «нормальныйРаспределение, потому что это так часто
Гауссово распределение может быть описано с использованием двух параметров:
- имею в виду: Обозначается греческой строчной буквой mu, это ожидаемое значение распределения.
- дисперсия: Обозначается греческой строчной буквой сигма, поднятой во вторую степень (потому что единицы переменной в квадрате), описывает разброс наблюдений от среднего значения.
Обычно используется нормализованный расчет дисперсии, называемый стандартным отклонением.
стандартное отклонение: Обозначается греческой строчной буквой сигма, описывает нормализованный разброс наблюдений от среднего значения.
В приведенном ниже примере создается гауссовский PDF-файл с пробным пространством от -5 до 5, средним значением 0 и стандартным отклонением 1. Гауссов с этими значениями для среднего и стандартного отклонения называется стандартным гауссовым.
Выполнение примера создает линейный график, показывающий выборочное пространство по оси X и вероятность каждого значения по оси Y. Линейный график показывает знакомую форму колокола для распределения Гаусса.
В верхней части колокольчика показано наиболее вероятное значение из распределения, называемое ожидаемым значением или средним значением, которое в этом случае равно нулю, как мы указали при создании распределения.

Функция norm.cdf () может быть использована для создания гауссовой функции кумулятивной плотности.









В приведенном ниже примере создается гауссовский CDF для того же образца пространства.
При выполнении примера создается график, показывающий S-образную форму с пробным пространством на оси X и совокупной вероятностью на оси Y.
Мы можем видеть, что значение 2 охватывает почти 100% наблюдений с очень тонким хвостом распределения за этой точкой.
Мы также можем видеть, что среднее значение нуля показывает 50% наблюдений до и после этой точки.

Формула кумулятивной функции распределения
Общая форма CDF, рассчитанная для дискретного случайного значения, имеет вид:
Fх (х) = Р (Х ≤ х)
Здесь X — вероятность, которая принимает значение, равное или меньшее x. Кроме того, диапазоном переменной X является полузамкнутый интервал (a,b], где a <b.
Отсюда мы можем написать вероятность в пределах этого интервала:
P (а < X ≤ b) = FИкс(б) – ФИкс(а)
Наоборот, если вам нужна CDF непрерывной случайной величины, ее общая форма задается следующим образом:
Fx(x) = -∞zfx(t)dt
Здесь X выражается через интегрирование функции плотности вероятности fx.
Кроме того, если распределение переменной X имеет дискретные компоненты при значении b,
Р (Х = б) = FИкс(б) – лимх→б- FИкс(Икс)
Вероятность и стандартное отклонение
Вы могли заметить, что интервал, выбранный в предыдущем примере, был равен одному стандартному отклонению выше и ниже среднего. Когда мы обсуждаем вероятности со ссылкой на интервалы, представленные в единицах стандартного отклонения, эта информация применяется ко всем наборам данных, которые следуют нормальному распределению. Таким образом, мы можем определить вероятностные характеристики, используя кумулятивную функцию стандартного нормального распределения, а затем распространить эти тенденции на другие наборы данных, просто изменив стандартное отклонение (или размышляя относительно стандартных отклонений).
Выше мы видели, что в нормально распределенных данных измеренное значение имеет шанс 68,27% попасть в диапазон в пределах одного стандартного отклонения от среднего. Мы можем продолжить обобщение нормально распределенных данных следующим образом:
- вероятность того, что измеренное значение будет в пределах двух стандартных отклонений от среднего, составляет 95,45%;
- вероятность того, что измеренное значение будет в пределах трех стандартных отклонений от среднего, составляет 99,73%.
Эти три вероятности дают простое представление того, как будут вести себя нормально распределенные измерения.
Пример кумулятивной функции распределения

Простой пример CDF — обычная монета. Предположим, что X является случайной величиной, которая говорит нет. исходов от монеты.
Мы можем дать вероятность монеты как:
Вероятность выпадения ни орла, ни решки = P(X≤0) = 0/2 или 0
Вероятность получить голову = Р(Х≤1) = 1/2
Вероятность выпадения хвоста = Р(Х≤1) = 1/2
Вероятность выпадения орла или решки = P(X≤2) = 2/2 или 1
Мы можем заключить, что значение вероятности монеты всегда находится между 0 и 1, что является непрерывным справа и неубывающим.
Полноценный пример приведен ниже:
f(x) =
Мы можем найти CDF вышеуказанной функции, используя следующие шаги:
Мы знаем это,
-∞f(x)dx = 1
k 01(x2 + x)dx = 1
к(х33+х22)01 = 1
к(56) = 1
Следовательно, k = 56
Поскольку CDF f (x) является функцией PDF, ее можно интегрировать с интервалом (-∞, х)
Итак, если x находится в интервале,
F(x) = -∞xf(x)dx
F(x) = -∞x 0dx
Так,
Ф(х) = 0
Если x принадлежит интервалу , то
F(x) = -∞xf(x)dx
F(x) = -∞0f(x)dx + 0xf(x)dx
F(х) = 0 + 65(х33 + х22)
Если x принадлежит интервалу (1, ∞),
F(x) = -∞xf(x)dx
F(x) = -∞0f(x)dx +01f(x)dx + 1xf(x)dx
F(x) = 0 + 65(x33 + x22)01 + 0
F (х) = 65 × 56
F (х) = 1
Таким образом, CDF определяется как:
F (х) = { 0 ; если х < 0; 65(х33+х22) ; если 0≤ х ≤ 1 ; 1; если х > 1}
Топ вопросов за вчера в категории Русский язык
Русский язык 01.05.2023 11:32 6451 Лосякова Юлия
Задание. Спишите предложения, расставьте знаки препинания, если они необходимы. Выделите причастные
Ответов: 2
Русский язык 30.04.2023 06:09 11572 Карпов Андрей
написать текст официально-делового стиля (7-10 предложений) СРОЧНО
Ответов: 3
Русский язык 20.06.2023 09:39 4025 Лозейко Саша
Замените несклоняемым существительным. 1 Музыкальный клавишный инструмент. 2. Род мороженого в шок
Ответов: 1
Русский язык 04.06.2023 15:27 10088 Лукьянова Вероника
Напишите текст в научном стиле 6-7 предложений.
Ответов: 2
Русский язык 03.07.2023 03:54 2220 Мерендзак Яна
Сочинение об осени с использованием метафор, эпитетов, олицетворения. (10 предложений) СРОЧНО! ПОЖАЛ
Ответов: 2
Русский язык 20.06.2023 02:37 2511 Богатова Дарья
Задание. Спишите предложения, расставьте знаки препинания, если они необходимы. Выделите причастны
Ответов: 1
Русский язык 01.05.2023 01:34 2608 Волков Андрей
составьте \»Словарь профессии\» из 15-20 слов, включив в него профессионализмы.Профессию выберите са
Ответов: 2
Русский язык 03.05.2023 18:29 710 Терентьев Никита
В каких предложениях выделенные слова являются причастиями? Выбери верные варианты ответа. Туман, оп
Ответов: 2
Русский язык 02.07.2023 02:15 1334 Балабушевич Евгений
Выпишите из текста (без пробелов и знаков препинания) все действительные причастия. Генерал думал
Ответов: 2
Русский язык 30.04.2023 06:36 2873 Кусь Иоанн
Выпиши сначала простые предложения,а потом сложные.Расставь знаки препинания.Подчеркни грамматически
Ответов: 2









Студенческий T-Distribution
T-дистрибутив Студента, или просто t-дистрибутив, для псевдонима «Студент» назван Уильямом Сили Госсетом.
Это распределение, которое возникает при попытке оценить среднее нормального распределения с выборками разных размеров
Таким образом, это полезное сокращение при описании неопределенности или ошибки, связанной с оценкой статистики населения для данных, полученных из гауссовых распределений, когда размер выборки должен быть принят во внимание
Хотя вы не можете напрямую использовать t-распределение Стьюдента, вы можете оценивать значения по распределению, требуемому в качестве параметров других статистических методов, таких как тесты статистической значимости.
Распределение может быть описано с использованием одного параметра:
количество степеней свободы: обозначается строчной греческой буквой nu (v), обозначает число степеней свободы.
Ключом к использованию t-распределения является знание желаемого количества степеней свободы.
Число степеней свободы описывает количество единиц информации, используемых для описания количества населения. Например, среднее имеетNстепени свободы как всеNнаблюдения в выборке используются для расчета оценки среднего населения. Статистическая величина, которая использует другую статистическую величину в своем расчете, должна вычесть 1 из степеней свободы, таких как использование среднего значения в расчете дисперсии выборки.
Наблюдения в t-распределении Стьюдента рассчитываются на основе наблюдений в нормальном распределении, чтобы описать интервал для среднего числа населения в нормальном распределении. Наблюдения рассчитываются как:
кудаИксэто наблюдения из гауссовского распределения,имею в видуэто среднее наблюдениеИксS — стандартное отклонение иNобщее количество наблюдений. Полученные наблюдения образуют t-наблюдение с (n — 1) степени свободы.
На практике, если вам требуется значение из t-распределения при расчете статистики, то число степеней свободы, скорее всего, будетn — 1, гдеNэто размер вашей выборки, взятой из гауссовского распределения.
В приведенном ниже примере создается t-распределение с использованием выборочного пространства от -5 до 5 и (10 000 — 1) степеней свободы.
Выполнение примера создает и строит график t-дистрибутива PDF.
Мы можем видеть знакомую форму колокольчика в распределении, очень похожем на нормальное Ключевым отличием являются более толстые хвосты в распределении, что подчеркивает повышенную вероятность наблюдений в хвостах по сравнению с гауссовой.

t.cdf ()Функция может быть использована для создания кумулятивной функции плотности для t-распределения. Пример ниже создает CDF в том же диапазоне, что и выше.
При выполнении примера мы видим знакомую S-образную кривую, как мы видим с гауссовым распределением, хотя с более мягкими переходами от нулевой вероятности к одной вероятности для более толстых хвостов.

Взаимодействие с внешними функциями
Аккумулятивная функция языка программирования в том числе может выполнять взаимодействие с внешними функциями. Это означает, что функция может использовать и вызывать другие функции, предоставляемые внешними библиотеками или модулями.
Взаимодействие с внешними функциями позволяет аккумулятивной функции расширить свои возможности и выполнить дополнительные операции или обработку данных, которые не предусмотрены в самой функции.
Аккумулятивная функция может вызывать внешние функции, передавая им необходимые аргументы и получая результат их выполнения. Также она может использовать функции из внешних библиотек для работы с файлами, базами данных, сетью и другими ресурсами системы.
Взаимодействие с внешними функциями обеспечивает гибкость и расширяемость аккумулятивной функции, позволяя разрабатывать более сложные и мощные программы с использованием функциональности, предоставляемой внешними ресурсами.
Получение данных
Язык программирования обладает аккумулятивной функцией, которая заключается в возможности получать данные из различных источников. При этом, такая функция позволяет языку собирать и сохранять информацию для последующего использования.
Функция получения данных в языке выполняет ряд задач. Во-первых, она позволяет получить пользовательский ввод, то есть данные, введенные пользователем с клавиатуры или через другие устройства ввода. Во-вторых, с помощью этой функции можно извлекать данные из различных файлов и баз данных. Например, язык может получать информацию из текстовых файлов, баз данных, API и других источников.
Одним из способов получения данных является использование функций и методов, предоставляемых самим языком. Например, в языке программирования Python можно использовать функции input() и open() для получения пользовательского ввода и чтения данных из файлов соответственно. Кроме того, различные библиотеки и фреймворки также предоставляют специальные функции и методы для работы с данными.
Часто при получении данных необходимо их обработать или преобразовать. Например, можно преобразовывать текстовые данные в числовой формат или выполнять другие операции над данными. Для этого язык предоставляет различные средства, такие как операторы и функции для работы с данными. Также можно использовать различные алгоритмы и структуры данных для обработки и управления полученными данными.
Таким образом, аккумулятивная функция языка позволяет получить данные из различных источников и использовать их для решения конкретных задач. Знание этой функции и умение эффективно работать с полученными данными являются важными навыками для программиста.
Отправка данных
Аккумулятивная функция языка играет важную роль в процессе отправки данных. Эта функция позволяет языку программирования накапливать и обрабатывать данные, полученные из разных источников, и передавать их по цепочке для дальнейшей обработки.
В чём заключается аккумулятивная функция в языке программирования? Допустим, у нас есть форма на веб-странице, в которой пользователь вводит своё имя и электронную почту. Для того чтобы отправить эти данные на сервер, нужно собрать их вместе и передать как один набор. Вот здесь и приходит на помощь аккумулятивная функция. Она помогает собрать все данные, введённые пользователем, в одну структуру данных, такую как объект или массив, и передать эту структуру на сервер.
Также аккумулятивная функция может использоваться для обработки данных перед их отправкой. Например, можно применить функции для проверки корректности введённой электронной почты или для преобразования данных в нужный формат. Все эти операции можно выполнять последовательно, добавляя каждую новую функцию обработки в цепочку аккумулятивных функций.
В итоге, аккумулятивная функция позволяет эффективно собирать, обрабатывать и передавать данные, обеспечивая гибкость и расширяемость языка программирования. Благодаря использованию аккумулятивной функции, процесс отправки данных становится более удобным и надёжным для разработчиков и пользователей.
Определение кумулятивной функции русского языка
Кумулятивная функция русского языка — это явление, которое характеризуется накоплением и сохранением лексического, грамматического и фонетического материала в процессе его развития. Это означает, что русский язык постоянно пополняется новыми словами, грамматическими правилами и произношением.
Кумулятивная функция проявляется в том, что русский язык стремится расширять свой словарный запас и использовать новые слова из других языков или разрабатывать новые слова на основе существующих корней и закономерностей. Кроме того, грамматические правила могут изменяться и реформироваться, а произношение может подвергаться изменениям.
Примерами кумулятивной функции русского языка являются:
- Введение новых слов из иностранных языков. Например, слова «смартфон», «интернет», «селфи» были заимствованы из английского языка для обозначения новых понятий и предметов.
- Образование новых слов на основе существующих корней. Например, слово «ученик» образовано от слова «учить» путём добавления суффикса «-ник».
- Изменение грамматических правил. Например, в русском языке произошли изменения в системе спряжения некоторых глаголов и склонения некоторых имен существительных.
- Изменение произношения. Например, произношение некоторых звуков может меняться со временем под влиянием соседних звуков.
Кумулятивная функция русского языка имеет огромное влияние на его развитие и способность адаптироваться к новым условиям и изменениям в обществе. Благодаря этой функции русский язык остается живым и актуальным, позволяя передавать новое знание и коммуницировать между людьми.
Мутация переменных
Мутация переменных — это изменение значения переменной в процессе выполнения программы. Она заключается в том, что функция изменяет значение переменной, которая ей была передана в качестве аргумента. Такая функция называется аккумулятивной.
Аккумулятивная функция может изменять исходное значение переменной для результата возвращаемого значения. Это позволяет использовать переменную внутри функции для хранения промежуточных результатов и последующего использования в дальнейшем.
Примером аккумулятивной функции может быть функция, которая суммирует все элементы массива и возвращает их сумму. Внутри функции создаётся переменная, которая служит аккумулятором, в которую при каждой итерации добавляется значение из текущего элемента массива. После прохождения всех элементов функция возвращает итоговую сумму.
Мутация переменных в аккумулятивных функциях позволяет более гибко использовать и изменять значения переменных в процессе выполнения программы. Однако, необходимо быть осторожным и правильно использовать мутацию переменных, чтобы предотвратить нежелательные побочные эффекты и ошибки в программе.
Изменение значения
В чём заключается аккумулятивная функция языка? Функция языка состоит в изменении значения, которое язык может иметь для его пользователя. Язык служит инструментом передачи информации, выражения мыслей и идей. При помощи языка люди могут изменять значения слов и символов, чтобы создать новые комбинации и отражать новые понятия и представления.
Изменение значения может происходить через различные механизмы, такие как метафоры, метонимии, механизмы импликации и другие стилистические приемы. Новые значения могут быть добавлены к уже существующим или заменить их полностью. Таким образом, аккумулятивная функция языка заключается в его способности развиваться и приспосабливаться к новым условиям и требованиям.









Кроме того, изменение значения в языке может происходить путем создания новых слов и выражений. Люди могут изобретать новые термины, которые отражают новые концепции и предметы. Это позволяет языку быть динамичным и отражать изменения в мире и в мышлении людей.
Перенос значения
Одной из основных функций языка, которая аккумулирует информацию и обеспечивает ее передачу и хранение, является перенос значения. Аккумулятивная функция языка заключается в возможности передавать значения между различными элементами языка, такими как переменные, функции, объекты и другие структуры данных.
Перенос значения позволяет использовать результат выполнения одного элемента языка в другом элементе, что в значительной степени облегчает программирование и создание сложных систем. Например, результат вычислений в функции может быть передан в переменную для дальнейшего использования.
При переносе значения между элементами языка часто используется оператор присваивания, который устанавливает новое значение для переменной или другой структуры данных. Также может использоваться передача параметров в функции или методы для обработки и изменения данных.
Аккумулятивная функция языка способствует созданию сложных программ и приложений, позволяя эффективно использовать значения и результаты вычислений. Благодаря этой функции программисты могут манипулировать данными, передавать их, изменять их состояние и получать необходимые результаты.
Примеры
В качестве примера предположим Икс{ displaystyle X} является равномерно распределены на единичном интервале ,1{ displaystyle }.
Тогда CDF Икс{ displaystyle X} дан кем-то
- FИкс(Икс)={ Икс<Икс ≤Икс≤11 Икс>1{ displaystyle F_ {X} (x) = { begin {cases} 0 &: x 1 end {cases}}}
Предположим вместо этого, что Икс{ displaystyle X} принимает только дискретные значения 0 и 1 с равной вероятностью.
Тогда CDF Икс{ displaystyle X} дан кем-то
- FИкс(Икс)={ Икс<12 ≤Икс<11 Икс≥1{ displaystyle F_ {X} (x) = { begin {cases} 0 &: x
Предполагать Икс{ displaystyle X} является экспоненциально распределенный. Тогда CDF Икс{ displaystyle X} дан кем-то
- FИкс(Икс;λ)={1−е−λИксИкс≥,Икс<{ displaystyle F_ {X} (x; lambda) = { begin {cases} 1-e ^ {- lambda x} & x geq 0, 0 & x
Здесь λ> 0 — параметр распределения, часто называемый параметром скорости.
Предполагать Икс{ displaystyle X} является нормально распределенный. Тогда CDF Икс{ displaystyle X} дан кем-то
- F(Икс;μ,σ)=1σ2π∫−∞Иксexp(−(т−μ)22σ2 )dт.{ Displaystyle F (х; му, sigma) = { frac {1} { sigma { sqrt {2 pi}}}} int _ {- infty} ^ {x} exp left (- { frac {(t- mu) ^ {2}} {2 sigma ^ {2}}} right) , dt.}
Здесь параметр μ{ displaystyle mu} среднее или математическое ожидание распределения; и σ{ displaystyle sigma} его стандартное отклонение.
Предполагать Икс{ displaystyle X} является биномиально распределенный. Тогда CDF Икс{ displaystyle X} дан кем-то
- F(k;п,п)=Pr(Икс≤k)=∑я=⌊k⌋(пя)пя(1−п)п−я{ Displaystyle F (к; n, p) = Pr (X leq k) = sum _ {i = 0} ^ { lfloor k rfloor} {n select i} p ^ {i} (1 -p) ^ {ni}}
Здесь п{ displaystyle p} — вероятность успеха, а функция обозначает дискретное распределение вероятностей количества успехов в последовательности п{ displaystyle n} независимые эксперименты и ⌊k⌋{ Displaystyle lfloor к rfloor ,} это «пол» под k{ displaystyle k}, т.е. наибольшее целое число меньше или равно k{ displaystyle k}.